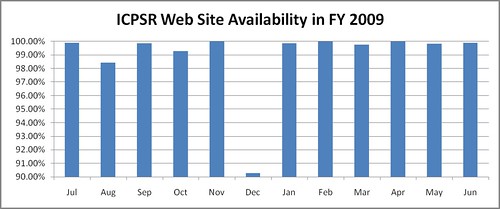
The first half of ICPSR fiscal year 2009 was a bit rocky. There was one long outage over a weekend in August 2008 where the portion of the web site that renders study descriptions and other dynamic content was not working, and there was a very long outage over the University of Michigan holiday break when ICPSR's building and other parts of Ann Arbor lost power for three days. Since that frosty, dark, cold holiday break we've made some changes to guard against extended outages.
One, we've implemented a 24 x 7 on-call rotation. The person carrying the pager that week is notified by the University of Michigan/Merit Network Operations Center (NOC) when any part of the ICPSR web delivery service has been unavailable for three minutes. This includes the actual web server, the database server, the search engine, and a handful of key web applications that we also monitor.
A recent interruption in service delivery occurred recently when it was my turn to serve in the on-call rotation. A Domain Name Service (DNS) server fault tripped up our web servers at 4:30am on Sunday, June 28, 2009, but because of the early morning page and follow-up phone call from the NOC, all service was restored by 5:00am. Just bringing someone's attention to problems in real-time during off-hours is enormously helpful in minimizing the length of an interruption.
Two, we've deployed a replica of our web systems in Amazon's cloud, Amazon Web Services. We tested the failover process in March, and used it again on May 14 when ICPSR once again lost power. In this case we lost power at about 3:30am on a Thursday, and it wasn't until nearly 1:30pm before we were able to fully recover. However, we were able to fail over to the replica in AWS at 4:30am, and so the outside world would have lost access to ICPSR data for only about one hour.
Because we've had such good success with AWS so far (and such lousy luck with the power in our building) we're likely to make the AWS replica our production system, and use our local system only for backup purposes before the end of this calendar year.
The reliability of the cloud and the transparency of the cloud providers has taken a real beating over the past year. (Here's a recent barb thrown at Google's App Engine cloud platform.) Our experience with the cloud has been very good so far: in addition to monitoring our production systems, the NOC also monitors our cloud replica, and the replica has enjoyed higher uptime than the production system.
My sense is that people are asking the wrong question. Is the cloud 100% reliable? Of course not. But is it more reliable than what you have today? Is it reliable enough to host one copy of your services or content? What's the cost to you (and your customers or members) to achieve 99% (or even 99.9%) availability using your own electrical and hardware infrastructure v. the cloud's?
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.